Please note that this is the first type of task described in this manual, and as such, it may be more detailed than those that follow. Our goal is to emphasize key points that might not be as thoroughly covered in later articles. For this reason, we recommend reading through this article carefully before diving into the task types that most interest you.
Minimum version
The simplest task type in the rqti package is single choice. A
template is automatically created when you initiate an rqti project
through RStudio. Alternatively, it can be added by clicking on
New file -> R Markdown -> From Template. The
rqti templates end with rqti. Here we look
at the templates singlechoice (simple) and
singlechoice (complex).
The minimum you need to provide is the type: sc (or the
equivalent type: singlechoice, or
type: schoice) in the YAML section and a list with at least
two elements in a section called # question:
---
type: sc
knit: rqti::render_qtijs
---
# question
An alpha error of 5% means that:
- There is a 5% probability that you will mistakenly reject the null hypothesis,
when it is actually correct. <!-- First option is treated as the correct one by
default. -->
- There is a 5% probability that the null hypothesis is correct.
- There is a 5% probability that you will mistakenly reject the alternative
hypothesis, when it is correct.
- The test power is 95%.
# feedback
The correct interpretation is:
There is a 5% probability that you will mistakenly reject the null hypothesis,
when it is correct.
This is based on the typical understanding of a 5% significance level in
hypothesis testing, which means that you are willing to accept a 5% chance of
making a Type I error.Note that in this example, a feedback section was also provided. This is optional, but usually it is a good idea to give some explanation for students.
Additionally, note that the knit parameter is set to a
custom rqti function, which streamlines the preview
process. While this is optional, it significantly simplifies the
workflow. Without it, the default preview will be a basic HTML file. By
including our custom knit function, you will get a more realistic
preview that allows for interaction with the task.
To preview the final result, simply click the Knit button in
RStudio (if you are not using RStudio, call render_qtijs on
the file). This will generate a QTI XML file and render it in the viewer
pane using QTIJS. If you are not using RStudio, you can also open the
server URL displayed in the console directly in your browser for the
same preview experience.
You can now interact with the task by selecting an option and then
clicking Submit in the top right corner. By default, after
submitting, the feedback and reached points are displayed:

The corresponding xml file is created in the same folder as the Rmd file if you click the Knit-Button.
Many learning management systems can directly import a QTI-XML-file, so all you need to do is upload the generated file. Compositions of tasks are covered in the article Sections and Tests.
If you happen to use OPAL/ONYX, you can also upload your tasks directly by modifying the knit parameter:
knit: rqti::render_opalThis will upload the file and open a browser with the OPAL url. It should look like this:

Setting up OPAL requires some additional steps, which are covered in the article Working with the OPAL API.
By default the rights of the uploaded material in OPAL are set to public, so no authentication is required to view the material. Otherwise you have to login into OPAL, which will log you out in the API. Please take this into account when testing your material. Without changing the defaults anyone with the link has access to your task.
Syntax explained
Let us have a closer look at the input file.
---
type: sc
knit: rqti::render_qtijs
---
# question
An alpha error of 5% means that:
- There is a 5% probability that you will mistakenly reject the null hypothesis,
when it is actually correct. <!-- First option is treated as the correct one by
default. -->
- There is a 5% probability that the null hypothesis is correct.
- There is a 5% probability that you will mistakenly reject the alternative
hypothesis, when it is correct.
- The test power is 95%.
# feedback
The correct interpretation is:
There is a 5% probability that you will mistakenly reject the null hypothesis,
when it is correct.
This is based on the typical understanding of a 5% significance level in
hypothesis testing, which means that you are willing to accept a 5% chance of
making a Type I error.Note that you do not necessarily need to specify which list element is correct. The first one is treated as the correct one, which is a useful shortcut. If you communicate this to your collaborators, it is also much easier to read. They do not need to look anywhere else in the file for checking the correct answer.
Of course you can specify the correct choice if need be. Our preferred way of doing this is by putting asterisks around this option. For instance:
Once again, this is much easier to read than providing the solution
somewhere else (e.g. in the YAML section). Furthermore, producing a
preview as HTML directly shows you which element is correct. If you want
to use italics in your choice, you can also wrap the correct solution in
emphasis tags:
<em> a choice with *some italics*</em>.
An important note: Do not forget to put a blank line before your question and the answer list, otherwise the list will not be a proper list:
Renders as:
A question text that is not separated by a blank line - A - B - C - D
More control
If you want to have more fine-grained control, consider the Rmd
template singlechoice-complex, which uses more YAML
attributes. In addition, you can also set feedback for correct and
incorrect responses.
---
type: sc # equivalent to singlechoice and schoice
knit: rqti::render_qtijs # if you do not want our preview renderer, remove this
identifier: sc001 # think twice about this id for later data analysis!
title: A meaningful title that can be displayed in the LMS
shuffle: false # random order of choices
orientation: horizontal # OR horizontal
points: 0.5
calculator: scientific # OPAL specific attribute
files: attachment.pdf # OPAL scpecific attribute
---
# question
Which version of the QTI standard is used by the R package rqti?
- 1.2
- *2.1* <!--Mark correct solution with asterisks-->
- 2.2
- 3.0
# feedback+
Nice. (Only displayed when the solution is correct.)
# feedback-
Try again. (Only displayed if the solution is not correct.)
<!-- If you prefer general feedback, just use the the section # feedback and
delete the other feedback sections-->Which renders in OPAL as:
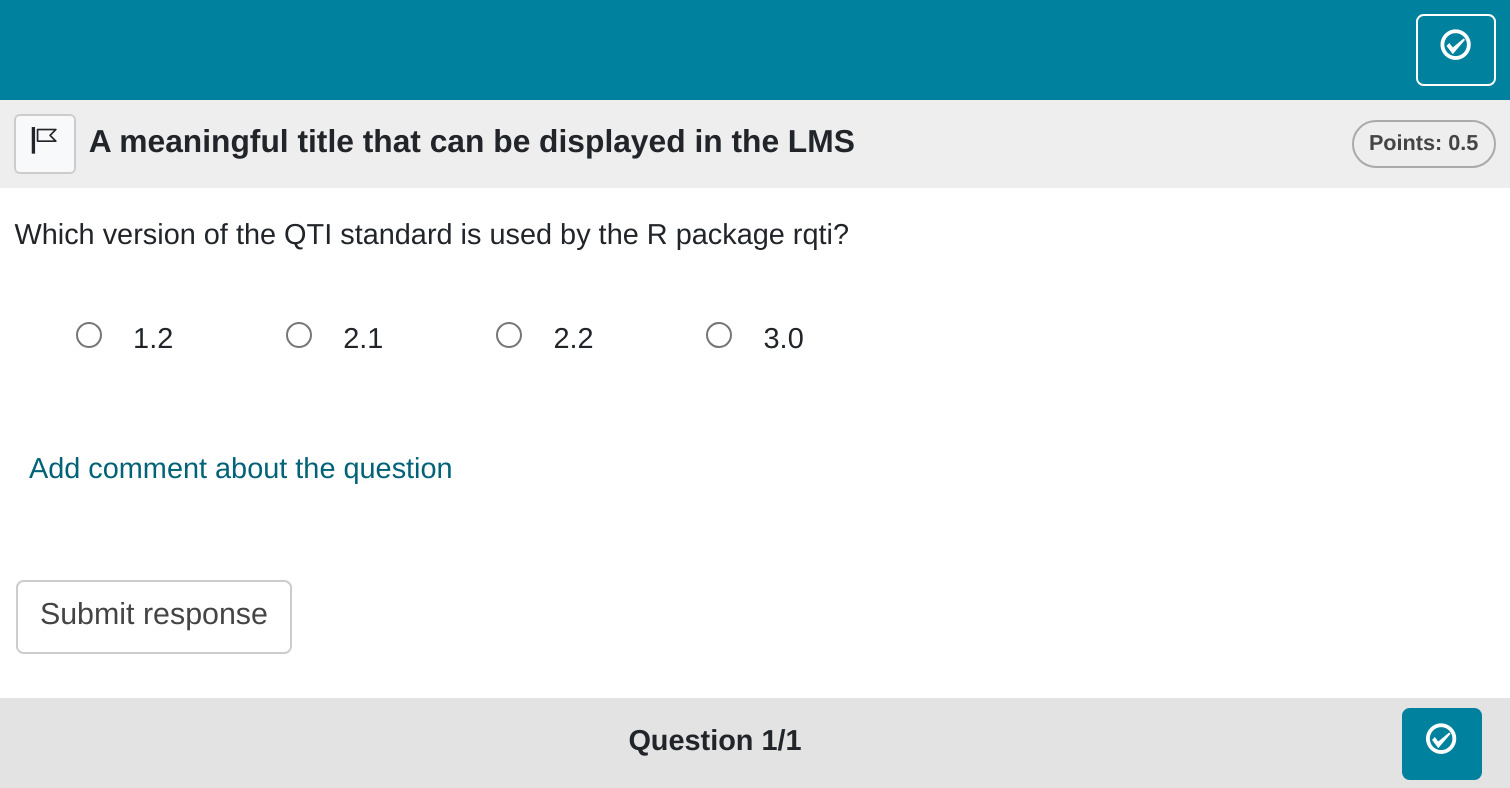
Notably, the choices are now displayed horizontally, and the title and points have been updated. The next section provides a detailed explanation of all YAML attributes.
YAML attributes
type
Has to be singlechoice or sc (a shortcut
for singlechoice) or schoice (compatible with
exams package)
identifier
This is the ID of the task, useful for later data analysis of results. The default is the file name. If you are doing extensive data analysis later on, it makes sense to specify a meaningful identifier. In all other cases, the file name should be fine.
title
Title of the task. Can be displayed to students depending on the learning management system settings. Default is the file name.
shuffle
If true (the default), randomizes the order of the
choices. Only in rare occasions it makes sense to have a strict order of
choices (setting shuffle to false).
calculator
If a calculator is required for this task, you need to assign the ‘calculator’ attribute the type ‘simple’ or ‘scientific’. This only works on OPAL.
files
If additional files are required to complete this task, you need to assign the ‘files’ attribute a single file path or a list of paths to these files. Keep these additional files in the same folder with Rmd. This only works on OPAL.
scoring_scheme
Two scoring schemes are available:
“standard” (the default): The respondent receives full points for a correct answer and 0 points for an incorrect answer.
“penalty”: The respondent receives full points for a correct answer. For an incorrect answer, a penalty of is applied, where is the number of answer options. This approach is often referred to as formula scoring, although the term is used inconsistently in the literature. Note that in Germany, the use of penalty scoring raises legal considerations; see, for example: https://nrwe.justiz.nrw.de/ovgs/ovg_nrw/j2008/14_A_2154_08urteil20081216.html
Feedback
Feedback can be provided with the section
- # feedback (general feedback, displayed every time, without conditions)
- # feedback+ (only provided if student reaches all points)
- # feedback- (only provided if student does not reach all points)
We typically prefer providing comprehensive feedback rather than
conditional feedback. Basically, we never use feedback+ and feedback-.
It is often more effective to present the entire solution, organized
into manageable chunks that users can expand or collapse, such as HTML
elements with <details> and
<summary> tags. To give an example:
<details><summary>Question1</summary>
Provide Feedback for Question 1
</details>
<details><summary>Question 2</summary>
Provide Feedback for Question 2
</details>will render as:
Question 1
Provide Feedback for Question 1Question 2
Provide Feedback for Question 2By clicking on the arrows, the details will unfold. Thus, there is no need to go beyond using the general feedback.
List of answers as a variable
For more complex tasks the list of answers is often just available as
a variable. In this case you can use the helper function
mdlist to convert the vector into a markdown list:
Some advice on single choice tasks
From a psychometric standpoint, single-choice tasks are often the least effective option for assessing ability. This is primarily because guessing cannot be entirely ruled out, leading to weaker psychometric properties compared to similar content presented in gap tasks.
For example, the exams package, an alternative R package
for test creation, frequently converts numeric gaps into single-choice
tasks. However, we believe this approach is justified only when the
learning management system either does not support gap tasks, provides
inadequate support, or the instructor requires printed exams with
automated grading. In all other cases, using numeric or string gaps is
generally more effective.
In some cases, single-choice tasks may be unavoidable. For instance, when determining whether a statistical test is significant, there are only two possible answers. In such situations, we suggest asking multiple related questions rather than relying on a single one. Additionally, assigning fewer points to single-choice tasks can help mitigate the effects of guessing.
If you have multiple single-choice tasks with identical answer options, consider using a match table instead (see article Table tasks).
In conclusion, it is advisable to avoid single-choice tasks whenever possible. Specifically, refrain from converting numeric gap tasks into single-choice format unless absolutely necessary. If single-choice tasks are unavoidable, consider asking multiple related questions or using a match table. Additionally, reducing the weight of single-choice tasks in the overall grading can help create a more balanced and fair assessment.